
While completely practical (and probably wise), there’s something a bit sad about the fact that Barack Obama will more or less be forced to give up e-mail access upon his ascension to the Presidency. E-mail communication has, in many ways, completely supplanted telephone communication in the 21st century; to me, this would be like telling any of the 20th century Presidents that they had to give up the phones on their desks. It seems like there must be a way to figure this one out…
I frequently find myself attached to some public wifi hotspot trying to get work done, and while I try to make most of my connections via secure methods (e.g., all my email takes place over encrypted connections), most of my web surfing takes place in cleartext. Occasionally, I’ll read some weblog post about the various hosted VPN services and think that I should just use one of them, but never really get around to it. This week, I finally bit the bullet… but rather than subscribing to one of the services, I just set up my own VPN server at home to use.
I have a Linux machine in my home network, and I flirted with the idea of installing OpenVPN on it and using that as my server, but due to a few weird complexities in where that machine sits on my network, that wasn’t the most appetizing idea to me. It was then that I wondered whether someone had built a VMware virtual appliance with OpenVPN support, and it turns out that PhoneHome was just the ticket I was looking for. On my home Windows 2003 Server box, I started that puppy up in VMware Player; it took about a half-hour’s worth of tweaking to get it set up just perfectly for me, and another half-hour to get my home firewall (well, really a Cisco router with a detailed set of access rules) set up to play nicely with the server. Now, I have an easy-to-run, easy-to-connect-to VPN server that allows me to have a secure connection no matter where I am, and that just rocks.
One of the things I was worried about was that the VPN would massively slow down my network connection; between the bottleneck of encrypting all the tunneled traffic and the bottleneck of my home internet connection, I was pretty sure I’d be less than impressed with the speed of an always-on VPN. Surprisingly, the connection is pretty damn fast, though — I appear to have the full speed of my home T1 available to me.

If anyone’s interested, I’m happy to share details of the changes I made to the PhoneHome VMware appliance, and any other info you might want.
A little bit ago, I wrote a piece about how a new start-up, Bit.ly, was ignoring the wishes of web content producers by creating cached copies of pages that are explicitly marked (by those same content producers) with headers directing that they not be cached. So here we are, three weeks later, and it crossed my mind that maybe Bit.ly had fixed the problem… and disappointingly, they appear to still not give a flying crap. (That’s their cached version of this page, a page that couldn’t make itself any clearer that it’s not to be cached.)
I hate to push this to the next level, but is it time to drop Amazon a DMCA notice saying that the page is copyrighted (as all works are, once they’re fixed in a tangible medium) and is being hosted on Amazon’s network?
(And one other thing: how annoying is it that when Bit.ly’s caching engine makes its page requests, it doesn’t send any user agent string, so it’s literally impossible for a website owner to identify the Bit.ly bot programmatically? They appear to be running the caching engine off of an Amazon EC2 instance, as well, so there’s not even a way to watch for a known IP address — it’ll change as they move around the EC2 cloud. Nevermind pissing in the pool; the Bit.ly folks are out-and-out taking a dump in the pool.)
There’s been quite a bit of press today about bit.ly, a new service from the folks at switchAbit; it’s a service that adds page caching, click-through counting, and a bunch of semantic data analysis atop a URL-shortening service that’s very much like TinyURL and others (and others!). Reading the unveiling announcement, the part that interested me most was the page caching part — they bill it as a service to help prevent link rot (i.e., when a page you’ve linked to or bookmarked then goes away), which would be a great service to those folks who rely on linked content remaining available. (And since they store their cached content on Amazon’s S3 network, robustness and uptime should be great as well.)
That being said, having worked with (and on) a bunch of caching services in the past, I also know that caching is a feature that many developers implement haphazardly, and in a way that isn’t exactly adherent to either specs or the wishes of the page authors. So I set out to test how bit.ly handles page caching, and I can report here that the service does a great job of caching the text of pages, a bad job of caching the non-text contents of pages, and a disappointingly abhorrent job of respecting the wishes of web authors who ask for services like this to not cache their pages.
For those who are all excited about Twitabit, the service that promises to queue up Twitter postings if the service is down, consider these two factlets:
- Twitabit asks you to type in your Twitter password — as in, you’re on a page on twitabit.com and asked to type in your password to another site entirely;
- Twitabit appears to have not one word of a privacy policy, or any other text that’ll help you understand why on Earth you should trust them with your password to another site.
Ummmm, no thanks. No thanks at all.
Because I run my own mail server, I’m able to watch for trends related to incoming email and crunch numbers on those that seem interesting. Today, listening to the voice which has been telling me for the past few weeks that spam feels to be on a major uptrend, I looked at the numbers of spam messages that have hit my own inbox. (Well, make that “tried to hit my own inbox,” since I’m also able to run a general spam filter whcih catches most of the unsolicited crap.) And that voice appears to be correct; over the past two months, I’ve received way more than double the number of spam emails than in any of the months in the first half of 2007. For example, I’ve received over 28,000 spams through today in November, compared to just under 12,000 in January.
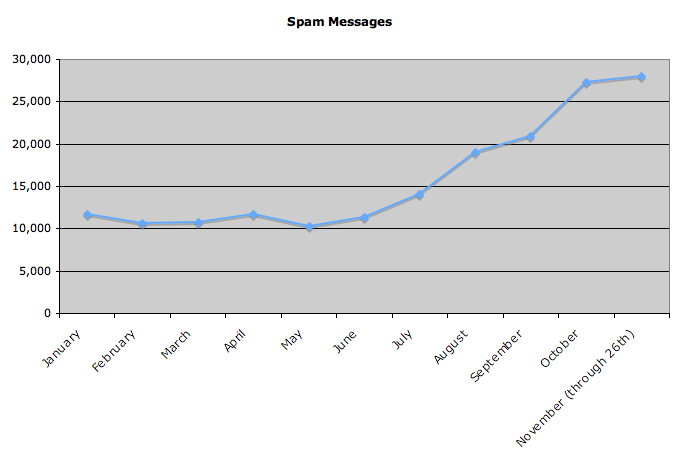
As always, stats can lie as much as they can reveal truth; I don’t know what my 2006 chart would have looked like, whether there’s always an uptick towards the later months of a calendar year, or any other such comparison information. Nonetheless, I figured this was interesting enough to share.
If the two-day Skype outage from last week was the result of a flaw in Skype’s own software, why did the company only release an updated Windows version of its client? What about the Mac and Linux users — does the robustness of the software on those platforms not matter?
Shannon and I have seen the TV ad for LifeLock a few times this weekend; it’s the piece where CEO Todd Davis shows his Social Security number all over the place, and then reveals that the only reason he’s comfortable doing so is because of his ultimate faith in his company’s ability to prevent its customers’ identities from being stolen. Of course, the ad made me curious enough to see whether his gambit has paid off — and unsurprisingly, it looks like someone succeeded in impersonating Davis and getting an online loan. Better still, Davis then coerced a confession out of the alleged identity thief, so Fort Worth police had to drop all charges against the guy and the district attorneys aren’t going to pursue prosecution. And the icing on the cake is that LifeLock’s co-founder, Robert Maynard, Jr., seems to be an identity thief himself, and was forced to resign his role at the company amid the allegations.
You can’t make this stuff up.
Aug 9, 2007 | Communications | DIY | Gadgets | Government | Internet | Law | Software | Web Design | Weblogs
I’ve got a few short takes today, to try to assuage my guilt for being a bit swamped these days (and also to get rid of a few of these tabs in my browser).
Remember the lawsuit Verizon filed against Vonage, threatening to bankrupt the upstart VOIP provider over technology the Baby Bell claimed was its own? It looks like Vonage might have finally rolled out workarounds to all the disputed tech, and also posted better-than-expected financials — which makes me pretty excited, being that I’ve been nothing but satisfied with our service from the company.
I’ve been slowly working my way through Jane Mayer’s amazing New Yorker piece on the CIA “black sites”, and it’s pretty clear that this is a must-read article for those who wish to learn how far our government has taken its torture of detainees in the all-important war on terror. The worst part of it is that at this point, there’s no question that what the public knows only scratches the surface, and that when tomorrow’s historians uncover the full details of this administration’s assaults on fundamental American liberties, we’ll either be aghast or will have long ago given up the right to express our outrage. (Let’s hope for the former.)
It’s amazing, but Apple really does look to be violating the script.aculo.us license on every single page that’s generated by the .Mac photo gallery. Either that, or they’ve struck some licensing agreement with the tool’s author, Thomas Fuchs — but seeing as how script.aculo.us is released under the extremely permissive MIT license, that’d seem unlikely for Apple to have done.
Cool — I hadn’t put two and two together, but Movable Type 4.0 is using Codepress to provide inline syntax highlighting in its template editors, and has extended the tool so that it recognizes all the Movable Type template tags. A long time ago, I bookmarked Codepress so that I’d remember to come back and take a look at it… looks like I don’t have to do that anymore. :)
Finally, this page might be dangerous for me. That is all.
Seriously, this is awesome. This morning, web hosting provider 365 Main announced in a press release that it had provided Red Envelope with “two years of 100% uptime at [its] San Francisco facility.” This afternoon, an outage in San Francisco left 20,000 without power, including 365 Main — and for reasons that are still unknown, no backup generators kicked in, knocking Red Envelope, Craigslist, Technorati, and all the SixApart sites (TypePad, Vox, etc.) offline for over two hours. Talk about the karmic boomerang coming around and smacking you on the ass…
Update: As of about 9:00 PM Eastern tonight, it appears that 365 Main took the press release out of the “In the News” section of their home page — seems like a good move.
Update #2: As of about 9:30 PM Eastern, they’ve also deleted the press release from their archives; seems like an all-out cleansing. Fishy!
I generally like his writing and his viewpoints, but I can’t help but wonder whether John Gruber’s missive against the enterprise’s wariness about iPhones is based more in his overt Apple lurve or in a lack of understanding of the things an enterprise has to manage on the wireless front. Far from his laser-like focus on email, when a large business thinks about services that need to be extended seamlessly to wireless devices, useful email access shares equal space with the ability to use a global address book, the need to access services on an intranet, ties into enterprise calendaring services, centrally-managed security policies, encryption (both of the contents of the device and communications between the device and other services), and the ability for the enterprise to control access on a device-by-device basis. And again, despite Gruber pointing out that some of the email issues can be solved using IMAP, there are few or no ways to solve the other issues, especially not in as unified a way as BlackBerry has done with the BlackBerry Enterprise Server (BES).
Let’s look at a few example issues, and think of how the iPhone would compare to what BlackBerry has in place.
1. A wireless user needs to be able to send an email to a few enterprise users, none of which are in his contact list. How does that user do this?
BlackBerry: in the email app, the user creates a new email, and in the “To:” line, types in the name of the recipient and chooses the “Lookup” option. The BlackBerry queries the global address list, returns a list of matches, and the user chooses the correct one, which is then added to the recipient list.
iPhone: according to articles like this, the iPhone doesn’t understand global address lists to the point where a developer had to write a raw LDAP client for the device (which we have to assume is a web-based app, given that there’s no native API for the iPhone). So the user has to open Safari, navigate to the web page which provides an LDAP lookup of the global address list, look up the user, and either click a mailto: link to start a new email to the user or cut-and-paste the address into the email client. (And while mailto: certainly is easier, it won’t work for multiple addressees without a really slick web app that allows multiple lookups to all be appended to a single link which will then launch the email app and start a new message. And none of this takes into account the fact that a company will have to write the LDAP lookup app in the first place.)
2. A wireless user needs access to an online database that only exists on a company’s intranet. How does the user get to it?
BlackBerry: given that the BES provides web connectivity that can be routed through the intranet, the user only has to open the BlackBerry Browser application and enter the URL, and will be taken to the web page hosting the database.
iPhone: there’s no similar way for iPhone users to route their web requests through an intranet server; iPhones get their connectivity to the internet through Cingular, and as such, are outside the enterprise firewall, meaning that they can’t get to intranet-only web applications. There’s no info on whether Safari on the iPhone will support the use of web proxies, but even then, use of the proxy will have to be open to the entire Cingular network, opening up a whole other host of security questions and problems. So to achieve this challenge, a company has to either (a) choose to host the web app on a server accessible to the internet at large and implement web-based authentication, (b) implement a public-facing webserver which has authentication and proxies requests for the application to the intranet server, or (c) set up an HTTP proxy server facing the internet and figure out how to secure it such that only authorized iPhone users can get access.
3. A company mandates that all wireless devices need to encrypt all information they store in memory, need to auto-lock after 15 minutes, and need to auto-erase the contents of the device after a given number of incorrect password attempts. In addition, the company wants to be able to wipe a device remotely that’s reported as lost.
BlackBerry: the system administrators create a new security policy with those three rules, push the policy out to all the BlackBerry devices registered on the BES, and then restrict access to the network to only those devices which have the new policy in place. All the devices receive the new policy and implement it; any devices which have more lax security settings are barred from accessing the enterprise. When a user reports their BlackBerry as lost, the sysadmins push a command to the device to wipe its memory.
iPhone: the system administrators recognize that (as of current information) there’s no way to encrypt all the information on the device, and no way to force the device to initialize itself after a given number of incorrect password attempts, so they give up on those two. They then send an email to all known iPhone users pleading with them to set their auto-lock times appropriately, and they hope that the users read the email and follow the directions. And given that it’s unclear whether there are any mechanisms of access control for specific iPhones, they continue to hope that the rules are being followed. As for lost iPhones giving up their data, there’s nothing that would allow for remote erasing, so the company also hopes that there’s nothing sensitive on the device.
4. Finally, given that I’m a physician, something that’s relevant to my world: an organization exists in a world which mandates that all electronic communications about patient care are encrypted from end to end, and system administrators are tasked with making sure their wireless devices comply with this requirement.
BlackBerry: the system administrators install the S/MIME add-on and the enterprise security certificate chain on all enterprise BlackBerries. They then have the users install their personal secure email certificate in their chains, as well, and then users can query the enterprise directory for other users’ secure certs and can choose encryption as an option on the email composition screen.
iPhone: from the bits of news coverage and reviews I’ve found, there doesn’t seem to be any encrypted email support on the iPhone, so there’s nothing the organization can do. It’s unclear whether the phone’s mail client can require — or even support — users’ connections to an IMAP server over SSL, so in addition to the actual email, the communications channel over which that email travels might be totally unencrypted.
There are oodles more issues that could be brought up, but the gist of the matter is that no matter how much people in the enterprise crave being able to replace their BlackBerries with iPhones, the support for the devices working at the enterprise level isn’t there. And given Apple’s pretty awful track record when it comes to integrating their other products into the corporate environment, you’d be naive to think that a seamless iPhone experience in the enterprise is coming anytime soon.
Ah, crapola: the Vonage verdict is in, and it bars the company from signing up any new customers during the ongoing patent fight with Verizon. Seeing as how Vonage loses 650,000 customers a year, and now can’t gain a single one for the foreseeable future, I’m pretty sure this is the sign of the apocalypse for the VoIP company.
My cursory research of other options for our home VoIP phone service brought me to the doorsteps of Packet8 and AT&T CallVantage, and then to two smaller companies, SunRocket and BroadVoice. Does anyone have experience with either? Specifically, the features I like a lot with our Vonage service are its rock-solid reliability (we’ve never had an outage or problem), the free calling to England (my sister and her family live there), and the feature where it attaches voicemail messages to email and sends them to us. Looking at the feature sets of all four of these options, it looks like the voicemail thing is pretty universal among them all, but only BroadVoice has a reasonable plan with free calling to England, and (of course) there’s no way to know about reliability other than asking for users’ experiences.
I’ll be the first to admit that I’ve only tangentially been paying attention to the lawsuit Vonage is involved in with Verizon — I knew that Vonage was found to have violated a few Verizon patents, but I had no clue that my home phone company might be forced to shut down its service this coming Friday! Apparently, in an effort to avoid a court-ordered shutdown, Vonage struck a deal with VoIP Inc. today to carry all its calls on VoIP’s network, a move that both companies claim routes around at least two of the technologies that Verizon has patented. But in the end, we still have a phone company that is a quarter of a million dollars in debt, now owes Verizon over $50 million for the use of its patents, and is churning through subscribers at increasing rates. So even if Vonage makes it through Friday — hell, even if the company makes it through the next few months — I’m not naive enough to think that I don’t need to be doing any research on who our next phone provider will be. Anyone have any suggestions?
Update: Clint Ricker has a bit more about the patents involved in the dispute over at IPUrbia.
One symbol of how amazing the internet has become is that you can saunter on over to the Internet Archive and download the original, very first recording of George Gershwin’s Rhapsody in Blue. (That’s part one, and part two is here.) It’s a digital conversion of the original 1924 acoustic recording — as in, a recording made by the pressure of the audio waves causing an engraving onto wax — and it’s simply awesome. For those who don’t speak the cryptic language of computer audio formats, the download you want is the “VBR ZIP”, which is a variable bit rate MP3 file that provides the best quality of all the files available from the Archive.
(And while the point of this post isn’t to lambaste the state of copyright in the US, it does serve to point out that we wouldn’t be able to listen to this amazing recording if the Congress of the mid-twentieth century treated copyright like our current one does. Since 1960, Congress has extended the length an artistic work remains under copyright eleven times, all at the behest of media and entertainment companies. Without some sort of change, it’s doubtful that our grandkids will be able to download recordings of the Gershwins of today without violating someone’s copyright, and that’s a true shame.)
When home users back up their computers, a lot don’t think about the fact that in some scenarios of data loss, those backups won’t do them any good — the scenarios which involve the loss of both their computer and their backups. (Think home fire, or burglary that involves taking the computer and the external hard disk that contains the backup.) For this reason, one tenet of most corporations’ backup plans is that an entire backup set exists off-site from the machines that are being backed up — safety through separation. There are hundreds of thousands of corporations who have the need to manage this process, so as a result, there’s a market of off-site storage providers that’s expanded and matured in a way that supports the importance of the data that’s being moved into storage. The big players have service agreements that stipulate the time frame in which customers can get their data, they provide reasonable guarantees for the safety of the data, and they put quite a bit of effort into meeting these guarantees.
In today’s day and age, home users are installing internet connections with more and more bandwidth, and this has opened up the potential that these users can actually back up their computers to some off-site location over the internet; unsurprisingly, a group of services has popped up to support this potential, services like .Mac, AT&T Online Vault, Mozy, and Carbonite, and even applications like JungleDisk and Amazon S3 which provide the infrastructure to allow users to take a more customized or do-it-yourself approach to online backups. As we’re talking about backups of people’s data, you’d think that these services would provide similar guarantees about the data’s availability and the services’ reliability, yes? Alas, that appears to be a false assumption. Ed Foster, everyone’s favorite griper, took a look at the end-user license agreements for a few of the online backup services back in mid-February, and he was pretty amazed to find that all the ones he investigated disclaimed pretty much any responsibility for the usability or availability of the backups, or even for the functionality of the services at all. (Granted, at least a few of the services he examined were provided for free — so in the end, you get what you pay for — but others are paid services.) That’s a real shame… but I’d imagine that it’s also an indication that there’s a real market niche waiting for the right company to come in and provide the right level of service.
Wow, does this Washington Post article make me feel old. The premise of the piece is that colleges now find it difficult to track down or get messages to their students, since most don’t have in-dorm telephones or voicemail and don’t check their college-issued email all that much. It’s a fact that I’ve now heard in different contexts a bunch of times over the past few months, and I feel like it’s the first concrete thing that makes me feel completely separated from today’s generation of young’uns.
I graduated from college just a hair over a decade ago, and during my four years, email went from mostly inaccessible to an essential staple of every student’s life. Talking to friends a few weekends ago, Shannon and I were stunned to learn that for most of today’s students, the term “checking email” has nothing to do with college email accounts, or even Gmail or Hotmail — instead, it means logging into Facebook or MySpace and reading your incoming messages. Similarly, while my university had digital phones with campus-wide voicemail in every dorm room (and used the system regularly to push out notices and information), a not-insignificant number of students at my alma mater today have never picked up their in-room phones, and actually don’t even know their own campus phone numbers. It’s amazing how fast things change.
That being said, these changes aren’t all that surprising, given that the fundamental roles of email and telephones have changed in college today. When I was in college, getting access to an email account wasn’t trivial; the free email services didn’t exist, the internet was new enough that setting up access to an email account was anything but trivial, and it took the infrastructure of colleges and reasonable-sized corporations to get most people into the fraternity of email users. Email was also novel enough that it was instantly appealing to college students, and there weren’t really any other options for talking to friends from back home (unless you wanted to pour money into your long-distance plan). Now, with instant messaging, social networking, and SMS-enabled cellphones, email is the least convenient of all the electronic communication methods available to college students (given the crushing amount of the erectile dysfunction spam, and what I’d imagine is an equally-crushing amount of college-related spam). Likewise, a decade ago, campuses used their functional monopoly power to satiate students’ need for phones in their dorm rooms, but today that monopoly is gone, and there’s little to recommend an in-room telephone when any student can get a cellphone for a lower price with more features and a more durable phone number. The rules of communication have changed, and it’d appear that colleges haven’t kept up… but it’d also appear that I’m getting old.
A few weekend short takes:
- How freaking cool is it that there’s a wireless internet service provider in Capitol Hill, with their primary service antenna about four blocks from us? We’re currently blessed with a dedicated and reasonably fast connection to the internet, but given a few hiccups we had with it over the past few months, it’s always nice to know that there might be a pretty easy alternative that doesn’t involve us signing our souls over to the local cable company.
- For a totally uplifting glimpse of a bit of musical history I had never heard of, take a listen to George W. Johnson’s “Laughing Song”. I learned about it from a MetaFilter thread that, as tends to be the case, fleshed out quite a bit more detail about the song; it was recorded sometime around 1902, digitized from its original wax cylinder by UCSB’s Cylinder Preservation and Digitization Project, and has inspired a few remakes and scary YouTube videos. (Weird YouTube subcultures scare me.)
- Not only is Anil Dash’s keynote from today’s Northern Voice weblogging conference already online, but if you click on the “Download” link above the keynote video, you can grab it in eleven different file formats. That’s damn cool.
- The folks at Yahoo are doing pretty amazing work lately with the Yahoo User Interface Library. This week saw the release of version 2.2.0, which brings with it three fab new controls. The Browser History Manager promises to help allow more interactivity in web apps while giving users predictable back button behavior, the DataTable control looks to be a great tool for displaying tabular data and letting users edit and sort it, move from page to page, and change their views on the fly, and the new Button control lets developers finally break free from the limited design and functionality of the buttons available through standard HTML forms controls. And better still, Yahoo is now offering to host all the relevant YUI files on their own servers for free, a pretty cool deal. I’ve used YUI controls in a few web apps and have always been impressed with their polish; I’m glad to see that far from becoming stagnant, the tools are moving forward in leaps and bounds.
- I think I need to own this. That is all.
What a smart idea! If you live within WiFi range of any Starbucks, the folks at FON want to give you a free wireless router so that you can share your connection with the customers at Starbucks. The bonus feature of the offer is that while the coffee chain’s own WiFi service costs $10 a day to use, using the FON connection would only cost people $2 a day, half of which goes to the user providing the wireless connection. Seems like a great way for FON to increase the reach of their social WiFi network, and for Starbucks customers to get access to the net for a hell of a lot cheaper — a win-win any way you look at it.
If you don’t live near a Starbucks but still want in on the free FON router action, don’t fear; it also looks like every registered FON user has three invitations to send which entitle the recipient to a freebie. So go find yourself a Fonero and ask for an invite!
(One caveat: while I have a FON router which works fine, I’ve heard a few horror stories about the setting the routers up, killing them dead with things as simple as a firmware upgrade, and wanting to throw them out of windows. The configuration interface also leaves quite a bit to be desired — it’s this totally weird mix where part of the config is done via a local interface to the router, and the other half is done via FON’s reasonably slow website which then sends it back to your router. I’m hopeful that it’s this sort of stuff that’s more indicative of them being new to the business and growing quickly…)
Over the past half-decade, there’s no denying that for all the amazing things the internet has brought us, it’s also been the source of quite a bit of annoying crap in everyone’s lives. From spam (\/|@GR@, anyone?) to phishing attempts to search results polluted with splogs to malware, a lot of people are out there exploiting the inherent trust model on which the fundamental internet protocols were based. What we’re all left with is an email system in which more than 9 out of 10 messages sent are spam, and with commerce websites and other online communities that have no way to trust their users other than to force us to create entire new identities on each of them if we want to use them. I don’t think it’s that wild a guess to say that many of us spend as much time each day dealing with all of these issues as we did performing their analogs in the non-internet-enabled world (driving to stores, writing letters, making phone calls), but today, the stakes are a lot higher — our family photos, bank accounts, and credit card numbers are all out there waiting for someone to exploit a hole in the armor and scurry off with them.
It’s because of this that I’m so happy to see an initiative like OpenID succeeding. A few years ago, the idea of OpenID was floated by the inestimable Brad Fitzpatrick (the father of LiveJournal, now a Six Apart property) as a way for people to carry around virtual identity cards on the net, and to securely use those credentials as a way of demonstrating to others on the internet who they really are. Between then and now, OpenID’s development has taken place out in the open, on mailing lists and wikis and web forums, and the result is a technology that Microsoft adopted last week and AOL has been quietly rolling out to its online service and instant messenger users for a few months now. That’s a great adoption rate, and I’d like to think that it’s because it’s a technology that’s sorely needed on today’s web. I’m not naive enough to think that it’s a salve to cure all the net’s wounds — for example, there’s still work to be done to make sure that anonymous ID providers don’t become the way spammers and miscreants get around the system — but I’m hopefuly enough to recognize that OpenID might be one of the more important building blocks to us all being able to trust our online interactions just a bit more.
Dear Yahoo:
As requested, this week I decided to merge my Flickr old-skool login with my Yahoo account. The process was painless and trivial to do, as advertised, and despite the massive how-dare-you-make-us-merge freakout that’s been flowing across the web, no part of my soul died in the process.
Once I was back in the folds of my Yahoo account, I decided to check my email and found that my account had been deactivated due to disuse. (This is not too surprising, seeing as how that account became a spam vacuum within moments of me opening it however long ago I did so.) What was odd to me was the way in which you offered me the various reactivation options — you did so without warning me in any way, shape, or form that one of the options costs money, and you provided me with no links to pages which might help me discover this fact. In many ways, this felt purposeful, as if you might want people to be lacking this bit of information while making what otherwise would be an obvious choice.

(Wily as I am, I managed to defeat your Jedi mind tricks by opening another browser tab and using Google to search for the truth before making my choice. And yes, the use of Google rather than your own search engine was purposeful; after all, I figured that not providing the information right there in the context of asking me to make the choice was a clear indication that Yahoo might not have the information to begin with, and thus it was unlikely to show up in your own search engine.) And therein I learned that opting for the first of the two choices would cost me 20 smackeroos, a fact that definitely shifted the balance a bit.
So I guess my point in all this is: while I was certainly glad to give you all the benefit of the doubt on the whole Flickr account merge issue, it didn’t help when you betrayed that trust by trying to trick me into a premium email service by withholding information at the precise moment I would need it in order to make an informed choice. You were this close to having a customer who was solidly baffled by the group of folks who question their ability to trust Yahoo with their Flickr accounts; instead, you managed to make me question whether it’s reasonable to trust you as a company. If you notice me keeping you at arm’s length for the next little while, even as you release cool new services I’m sure I’d love to play with, I hope you understand…
Regards,
Jason
As a pseudo-update to my astonishment at the cost of wireless network access in the Orange County Convention Center, I heard an even better story from another participant in the conference. She represents a small publisher, and had reserved a tiny room in the main conference hotel in which she could meet with all her authors and hammer out their business for the year. She asked the hotel to activate the in-room network access, and was quoted the price of $1,200 a day — that’s not a typo. The same hotel offered building-wide access to guests for $8 a day, so she just asked one of her authors who was staying at the hotel to activate their access and used that.
$1,200 a day?!? Seriously, for that daily price, you could get two T1 lines run to the location of your choosing and pay the monthly cost of the lines. That’s simply insane.
Nov 5, 2006 | Internet
In order to explain the poor state of internet connectivity here at QDN (and for you handful of people who use the mailserver that lives here), I present this graph of the availability of my home internet line for the past 24 hours, a line that’s graded as business-class and which costs more than my monthly car payments:

Whaddya think, worth the money?
I’m pretty sure that the main qualification for being appointed head of IT for any of the popular marathons is a complete inability to anticipate people’s desire to use online services to track runners. Take today, for example; in my 50 to 100 attempts to load the NYC Marathon Athlete Tracker over the past hour, I’ve had the page successfully load and render a sum total of five times. Or take last weekend’s Marine Corps Marathon, where the reliability of the athlete information site was a slight bit better, but the system which sends alerts via text messaging was spotty at best (the norm was to get an alert somewhere around 15-20 minutes after a runner passed a waypoint). In my three years of living in Massachusetts, the site for the Boston Marathon always became unusable within 20-30 minutes of the official race start, and last year I didn’t get a single text message update for the people I was tracking.
In today’s day and age, the technology and knowhow certainly exists to build a reliable site capable of handling a short-term heavy load; given that every single popular marathon decimates the IT systems meant for public use, how long will it take for a company like Google or Yahoo to step in and solve this problem?
This morning, I took a look at my mail server logs to see if yesterday’s changes had caused any unexpected issues, and I’m happy to say that all appears well. I also took a few minutes to analyze the logs a little bit, and here’s what the past 20 hours has brought:
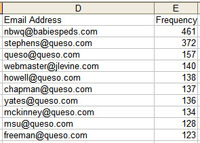
- In 1,202 minutes, 16,605 messages were attempted to be delivered to nonexistent accounts on my server, for a rate of one message every four and a half seconds.
- Those 16,605 messages were addressed to 915 unique (and still nonexistent!) email addresses.
- By far, the queso.com address bore the brunt of this, with 759 of the addresses living there; no other domain had more than 60 or 70 false attempts.
- The most popular fake email address is one that’s never existed, and doesn’t make much sense at all; it received 461 attempts. (The top 10 list is in the graphic to the right.)
- As you’d expect, generic “webmaster” email addresses are popular, accounting for 225 of the attempts across all the domains I host; “postmaster” and “mail” are a lot less popular than you’d think.
All in all, I’m glad to have made the configuration change, and my mail server seems to be operating under quite a bit less load as a result.
There’s really no debate that despite all efforts to combat it, spam email continues to grow and thrive on the internet. Since I host my own email server (providing accounts for myself, my family, and a few friends), I’ve watched as gargantuan volumes of unsolicited email stream in over the wire, and I’ve had to keep up to speed on the latest and greatest spamfighting techniques in order to keep our mailboxes reasonably free of the nuisance. That being said, the whole system has always felt like a fragile beast, and when my spam system fails for even a few minutes, my inbox can get buried. (For example, a component of my filters got overloaded this morning for just over six minutes, and over 50 spam emails slipped through in that period.) So, for the past year, I’ve been hunting for ways to optimize my mail setup in order to lessen the load on the spam filters, and one specific way has eluded me until this morning. Being that I’ve actively searched for this very solution for over a year and not had success until today, I figured I’d describe what I did in case anyone else is looking for the same fix.
(Really, I shouldn’t have to tell you this, but what follows is an extremely detailed, low-level description of my mail setup and the innards of a spam filtering system. It’s dorky, and you probably won’t want to read the rest unless you’ve imbibed a good deal of caffeine and know your way around sendmail.)
One little bit of advice: do yourself a favor and give Firefox 2.0 RC3 a try. Over the past month or two, a few people have told me how much faster the new version of Firefox is when compared with the current v1.5, but I didn’t believe them until I finally got around to installing it last night — it’s amazingly peppy, and it’s been rock stable on the few machines on which I’m now running it. I’ve always found the page rendering part of web browsing to be a bit lethargic on my Macs; Firefox 2 feels comparable to Windows browsing, which is mucho mejor. It’s good enough that I’m changing my default Mac browser back from Safari to Firefox.
(And since my biggest fear about the upgrade ended up not being a big deal at all, I’ll mention that all of the extensions I use regularly — the Google Toolbar, Firebug, Greasemonkey, the del.icio.us extension, the Web Developer Extension — have updates available which are compatible with the new Firefox. The only extension in my installation that didn’t have a Firefox 2-compatible version was Live HTTP Headers; it’s not one I use on a day-to-day basis, though, so I’m OK with leaving it out of my install until it comes up to speed.)
Waiting for a flight Thursday evening, I opened up my Powerbook to see if the Gods of Wireless Networking had yet talked some sense into the folks who run Washington’s National Airport. Alas, there weren’t any legit wifi signals available — I specify “legit”, though, because there were quite a few ad-hoc networks set up that looked to be trying to phish and scam their way into information from unsuspecting or naive flyers.

If you look at that list, what you’ll notice is that all of those networks are running in “ad-hoc” (or peer-to-peer) mode, which almost certainly means that rather than them being bona-fide wireless access points serving up connections to the internet, someone’s computer is advertising its own wireless network as available for sharing, and that person is trying to get you to connect to it. That network named “tmobile” is very unlikely to be run by T-Mobile; that network named “Starbucks” is similarly illegitimate. Instead of T-Mobile providing access to the internet, some schmuck is probably trying to entice you to connect your laptop to his, which means that he can then listen in on all your network traffic (sniffing passwords and other data) with relative ease.
Almost without exception, all trustworthy wireless access points run in what’s called “infrastructure” mode. The list of networks in that screenshot is generated by an awesome Mac app named iStumbler, but the built-in networking stuff in any Windows or Mac computer similarly makes a distinction between ad-hoc and infrastructure networks — the Mac separates ad-hoc networks into their own list (“Computer-to-Computer networks”), and if I remember correctly, Windows shows ad-hoc networks with different icons than infrastructure ones. So if you find yourself looking to use wireless access in an airport, make sure you know how to tell the difference between reasonably legitimate networks and scammers; your credit cards, bank accounts, personal files, and email systems will thank you!
Interesting: Google Apps for Your Domain. Veeerrrrrryyyy interesting. It’s hosted Gmail, chat, calendering, and web design all under the banner of your own domain name, all currently in beta-test mode. Unsurprisingly, Anil does a better job of reviewing the landscape than I’d ever be able to do.
Aug 22, 2006 | Internet
A very wise friend once taught me a Cisco configuration command that I should carry around on a laminated card in my wallet:
copy running-config startup-config (or copy run star)
reload in 10
A little background:
I have a high-speed digital line providing my home internet access, and a Cisco 4700M router that sits at my end of that line. The router is powerful enough that I use its packet filters as a crude firewall in front of a few of my machines, and as I add or remove services on those machines, I need to make changes to those filters. As often as not, I’m doing this from someplace outside my home — meaning that I’m (stupidly) making changes to the router’s access rules over the very internet connection to which those access rules apply. And there have been about a dozen instances — this afternoon being one of them — when a typo or mistake on my part has created a rule that essentially shuts down any traffic over the connection… so that all of my servers are essentially deaf to the world, and the only recourse is to come home and fix the mistake via a direct connection to the router.
So now, what’s so good about the reload in 10 command? If you issue that command before trying to make any configuration changes, that sets the router up to reboot itself in 10 minutes. During that 10-minute window, you can make any configuration changes you want, and so long as you don’t save the new config to startup, any problems will be wiped away once the box restarts itself. If you make all the changes you need before 10 minutes passes and you’re happy with the results, you can just issue a reload cancel command, and you’ll be all set.
Now, if only I could follow my own advice…
For me, part of moving onto a new job has always been getting electronically settled-in — getting my new email address, figuring out how to connect to my centralized file shares (and asking which of them get backed up regularly!), and learning what other network resources are available for me to use. In my new job, I’ve picked up that keeping my calendar on the central Exchange server is going to be more than a little bit useful… and that it’s probably time for me to figure out once and for all how to make the mishmash of calendars and schedules in my life work together in a way that’s actually usable.
At this very moment, I have bona-fide calendars living in too many different places — on the aforementioned Exchange server at work, within Google Calendar, and on my PalmPilot. Each lives where it does for a reason; the Exchange server is obvious, the Google calendars were started by Shannon and me when we realized that we were desperate for a way to coordinate our lives, and my PalmPilot calendar is my original life planner, with information going all the way back to August 10th, 1998. I also have a few different interfaces for the calendars, like Outlook, Google Calendar, and iCal. Since iCal is the repository for the Palm information (thanks to The Missing Sync) and can pull in the Google Calendar data, it’s as close to a complete picture as I can get in one app… but since it can only read from Google Calendar, and can’t write back to the service, I still have to switch to a web browser a million times a day to add and update that information. As a whole, the situation is as suboptimal as things can get, and I’ve spent the past few weeks trying to figure out a solution that might help me bring everything together in as seamless a way as possible. (Given that I’ll have an additional tool added into the mix in the next week or two, I’m anxious to solve this!)
My ultimate dream setup would be to have my work calendar live on the Exchange server and synchronize to Google, to have my personal calendar living at Google, and to have the ability to use any of the interfaces — Outlook (and Outlook Web Access), GCal, iCal, the BlackBerry — to view and update any of them. Right now, this is hampered by Outlook not natively doing the GCal thing, by iCal only being able to subscribe in a read-only way to GCal, and by me not having the BlackBerry yet (so not knowing what the heck it can do). Something like Remote Calendars might help me on the Outlook/GCal side of things, but it looks like it’d require a Windows machine running Outlook 24/7 in order to make it work the way I want. As for a two-way link between iCal and GCal, there seem to be a lot of stupid hacks out there, but nothing close to prime-time (which is surprising given that the Mac has an extensible synchronization app, iSync, to use as a foundation). I’m not sure that I’ll ever be able to make all these apps play well together, but I’ll fill in the blanks as I try to figure it out.
Two weeks ago, I expressed some amount of happiness that SightSpeed was releasing the latest version of their video chat software, a version that ostensibly improves the quality of the video enough to perhaps put it on par with that of Apple’s iChat/iSight combo. I’m now here, with four or five lengthy SightSpeed chats under my belt over the past week, to say that the company’s claims are completely true — SightSpeed 5.0 video chats are just plain awesome. The quality held up not only on Mac-to-Mac (iSight-to-iSight) chats, but also on Mac-to-PC chats, and I had not one lick of trouble using SightSpeed through the home router firewalls that existed at both ends of all the chats. I’m ecstatic… it seems like it took way too long to happen, but cross-platform video chat appears to have finally made it to the big leagues. This means that my parents are now going to get to video chat with my sister and her family in London — and that tonight, Shannon and I got to spend an awesome half-hour chatting with our best friends in Brookline and their twin five year-old sons. Life is so much better!
If you’re interested in high-quality, cross-platform video chat, then grabbing SightSpeed is pretty much mandatory for you. And in my experience, the crap that has been passed off as reasonable-quality in the PC-to-PC video chat world pales in comparison to what I’ve experienced over the past week, so if that’s your world, then moving up to SightSpeed is probably worth it for you as well. Feel free to share your experiences!
Continuing with what’s slowly becoming an obsession for me, the task of finding a video chat solution that actually works worth a damn between Macs and PCs, it appears that the folks at SightSpeed are releasing their newest version tonight. Why do I care? Because rumor has it that version 5.0 brings with it a huge improvement in the quality of the video, an improvement that might hold cross-platform promise. (That PC Magazine review is a bit over the top, though, with comments like “No other services, not even those from the big guys (AOL, Microsoft, Skype, and Yahoo!, among others), have developed their video codecs to the degree that SightSpeed has” — the author’s prior experience is clearly limited to PC-only apps, and has neglected to see the remarkable quality and performance that comes from an iSight-to-iSight conversation over AIM.) As before, as soon as I can get my hands on SightSpeed 5.0 (and a little chunk of time), I’ll give it a test and report back.
Hallelujah — Skype has finally released a beta “preview” version of its Mac chat client that includes video support. I’ve complained in the past about the shameful state of online video chat between Macs and PCs, and wondered whether Skype’s eventual entry into the world of Mac video support might provide a decent alternative to the crap that’s currently out there; I’ll be sure to report back once I get a chance to test this out. (My most trusted tech-savvy video chatter is currently vacationing in Germany!)
Update: OK, without my trusty buddy with his PC and webcam, Matt and I gave the Skype preview a shot between two Macs, and I gotta say I’m not all that impressed — his words were that it feels like iChat 1.0, and my observation was that the video was choppy and stutter-prone, and the audio had a lot more echo than I’d think would be tolerable for long. The big caveat is that I’d have to imagine there’s a lot of debug code (and lack of optimization) in this preview release, so we’ll see where things head.
Today, my kid sister and her family moved to London, for at least the next two years. She has a great husband and two awesome kids, and even though they lived in New York City up until now, we’ve gone down to visit a ton over the past few years and have had a blast watching the kids grow up. So, needless to say, the idea of the whole bunch of them being so far away makes Shannon and me pretty sad, and we’ve been putting a lot of time into figuring out the best way to be able to video chat with them. When we’re just talking about us — Shannon and me chatting with Rachel and her husband and kids — things are simple, since we both have Macs with iSight cameras, and iChat couldn’t make things any easier. Of course, it’s now grown into more than just us; my parents and my brother and sister-in-law would also like to partake in the chats, and all of them are on Windows-based PCs. And as things turn out, it’s much more difficult to setup a Mac-to-PC video chat, and for it to match the quality of a pure Mac/iSight chat.
We started out by buying my parents a Logitech Quickcam for Notebooks Pro and installing AOL Instant Messenger. (We’re thinking about a Creative Live! Voice webcam for my brother and his wife.) I figured that things would just work fine, but quickly learned that that was an idiotic assumption; my first sign that there would be problems was when I noticed that the latest version of AIM, AIM Triton, is an enormously bloated bit of crapware that shares almost nothing in common with the application that we all know and tolerate. After getting through its painful setup process and ignoring all the entreaties to sign up for new services, I found the instant messaging component of Triton and added my sister to the buddy list. And despite being in the same house — and on the same network — as my sister’s Mac, I was unable to establish a video session between the two computers… because it turns out that Triton breaks all compatibility with iChat. Sigh.
Next, I tracked down and grabbed the older (and more compatible) version of AIM, and installed that. It had no troubles using the camera and establishing a video connection with my sister’s Mac, but the quality was middling at best (remember that we were even on the same network!), the video window was tiny, and there was no way to enlarge it. Double sigh.
Finally, I remembered that Trillian Pro, the alternative Windows instant messenger multi-client, had video chat abilities, so I downloaded and installed it. (Fortunately, I still have a license from back when my primary laptop was a PC.) It too was able to set up a video connection between the PC and Mac, and while the quality was equally middling, the window could be resized so that at least my parents didn’t have to squint to see that video. After a bit of optimizing the camera settings, we got a usable connection set up, so for now, that’s the solution we’re going with for all the non-Mac users.
But this begs the question: what are we missing? There have to be better options out there. For now, Skype only offers video on its Windows client, so that’s out. There are a couple of free video chat apps that work on both PCs and Macs (SightSpeed and Yak have been mentioned here and there), but I have no idea if they work any better than AIM’s offering. Likewise, there are a couple of commercial cross-platform clients (iSpQ, iVisit), but I’d have to know a lot more to recommend spending money on either to my family. And most importantly, any other solution needs to be reasonably easy to set up and to use when starting or accepting video chats.
So, does anyone have any thoughts?
May 4, 2006 | Internet
Doesn’t that just figure — on the day that I post about a network outage at Six Apart, my own network connection decided to become fiercely flaky.
It turns out that responsibility for my digital line is a bit tricky — I pay my ISP for the line, and they subcontract with two different telcos for different parts of the line (the part that goes from our house to the local central office is managed by Verizon, and the part that goes from the central office back to the ISP is managed by MCI Worldcom). After everyone came into agreement that the problem was on Verizon’s portion, the tech came out this morning and isolated it to a single span of wire that failed during yesterday’s rainstorm here in Brookline. He switched out the span, and now that it’s testing clean again, we should be back in business. Sorry for the spotty outages!
There was quite a bit of teeth gnashing across the web throughout the evening yesterday as TypePad, LiveJournal, and all the other hosted Six Apart websites went dark; we learned late in the night that the cause was a “sophisticated distributed denial of service attack” against the sites. Digging a little deeper, though, it doesn’t look like this is a particularly accurate description of what happened — but instead of this being a case of the folks at Six Apart trying to cover up some internal issue, it instead looks like they’re being far too gracious in not revealing more about another company, Blue Security, which appears to have been responsible for the whole disaster. An explanation of this requires a slight bit of background.
Blue Security is a company which has recently garnered a little bit of notoriety on the ‘net due to its unorthodox method of attempting to control the problem of spam email. Last summer, PC World publshed a reasonably good summary of Blue Security’s antispam efforts; a charitable way of describing the method would be to say it attempts to bury spammers in unsubscription requests, but a more accurate description would be that the service performs outright denial-of-service attacks on spammers, and does so by convincing people to install an application (Blue Frog) on their computers which launches and participates in the attacks. Without a doubt, Blue Security’s system has generated controversy from the perspective of both unsolicited emailers and regular ‘net citizens alike, so it’s not all that surprising that the spammers recently began fighting back. One of the methods used against Blue Security has been a more traditional denial-of-service attack against the company’s main web server, www.bluesecurity.com, an attack which was effective enough to knock that web server offline for most of yesterday.
OK, so why is any of this information — about a company completely unrelated to Six Apart — important background? Because according to a post on the North American Network Operators Group mailing list, at some point yesterday the people at Blue Security decided that the best way to deal with the attack was to point the hostname www.bluesecurity.com to their TypePad-hosted weblog, bluesecurity.blogs.com. This effectively meant that the target of the attack shifted off of Blue Security’s own network and onto that of Six Apart, and did so as the direct result of a decision made by the folks at Blue Security. (The best analogy I can think of is that it’d be like you dealing with a water main break in your basement by hooking a big hose up to the leaking joint and redirecting the water into your neighbor’s basement instead.) Soon thereafter, the Six Apart network (understandably) buckled under that weight and fell off the ‘net, and over four hours passed before packets began to flow again. (And given that the www.bluesecurity.com hostname was still pointed at TypePad for most of today, I’d imagine that the only way those packets began to flow was as the result of some creative filtering at the edge of its network.) Judging from the outage, it’s unlikely that Blue Security gave them any warning — although who knows whether a warning would’ve prevented the basement from filling up with water all the same.
So, returning to my original point: saying that Six Apart’s services were taken down as the result of a “sophisticated distributed denial of service attack” is an incredibly gracious statement that only addresses about 10% of the whole story. The other 90% of that story is that Blue Security, a company with already-shady practices, decided to solve its problems by dumping them onto Six Apart’s doorstep, something I’m pretty damn sure isn’t part of the TypePad service agreement. I know that ultimately, the denial-of-service attack came from the spammers themselves, but it was specifically redirected to the Six Apart network by Blue Security, and I hope that they get taken to the cleaners for this one.
(I’ve just begun experimenting with the social bookmarking/commenting site Digg; as I’m clearly in favor of more people understanding how the outage came to occur, feel free to Digg this post.)
Update: Computer Business Review Online has picked up the story, and has some other details. Netcraft also has a post on the DDoS, and News.com picked up the bit from them, but there’s not much more in either bit.
May 2, 2006 | Communications | Internet
Holy crap — Vonage announced today that its premium plan now includes unlimited calls to a big chunk of western Europe! Shannon and I have been thinking about using Vonage for our phone service; with my sister and her family moving to London in a month, I think that this announcement seals the deal.
Tonight, an email to a friend of mine was rejected from the comcast.net mail servers, sent back with a notice that my mail server has been blacklisted by the good folks at Comcast “for abuse.”
----- The following addresses had permanent fatal errors -----
(my cousin's email address)
(reason: 550-209.10.108.200 blocked by ldap:ou=rblmx,dc=comcast,dc=net)
----- Transcript of session follows -----
... while talking to gateway-r.comcast.net.:
MAIL From: (my email address) SIZE=4602
<<< 550-209.10.108.200 blocked by ldap:ou=rblmx,dc=comcast,dc=net
<<< 550 Blocked for abuse. Please send blacklist removal requests to blacklist_comcastnet@cable.comcast.com - Be sure to include your mail server IP ADDRESS.
554 5.0.0 Service unavailable
I administer my own mail server, and can tell you with absolute certainty that it’s not involved in any abuse directed the way of Comcast, so this was a bit confusing. I sent off an email to the address in the response, providing the information that was requested and asking for an explanation.
Hello -- I just tried to send an email from my mail server to a colleague on comcast.net, and received a reply that my mail server has been blacklisted. (I am the administrator of the mail server; it's mail.queso.com, also known as fondue.queso.com, IP address 209.10.108.200.) Can I please learn why the server has been blacklisted? I'd appreciate logs of any suspicious activity that you've seen, if that's the cause of the blacklist.
Please get back to me at your soonest convenience; this is actually a reasonably large problem.
Thank you.
I then went to my good friend Google to see if I could better understand what had happened, and learned that I’m far from the only one who’s experienced this idiocy. Hidden-Tech appears to have been blacklisted regularly, as has HSH Associates, TechPro, and even the esteemed Wil Wheaton (hell, the TechPro people had to have their attorney participate in phonecalls to Comcast before they were able to get the problem solved!). After reading those, it didn’t surprise me at all to hear my email notification ding and find this in my inbox:
Please do not reply to this message.
We have received your request for removal from our inbound blacklist. After investigating the issue, we have found that you did not include the IP address to be removed.
We need the IP address that you believe is currently blocked to further investigate this issue.
Please verify the IP and resubmit your request to blacklist_comcastnet@cable.comcast.com.
So, what I’ve learned is that not only does Comcast suck at administering its own email system, it sucks at the simple task of writing a tiny app to find an IP address in an email. It’s unfortunate that both my inlaws rely on Comcast for their email addresses — I guess it’s time to move them over to something a bit more competently-managed.
Update: I sent another email, this time with the IP address alone on its own line, and again got a reply saying I didn’t send the address. I hate Comcast; maybe it’s time to just block all incoming email from comcast.net and be done with it.
Update 2: I sent two more emails, trying to decipher the super-secret method Comcast’s using to find the IP address (on a blank line? prefixed by “IP ADDRESS”? on the subject line?), and both garnered replies that claimed I didn’t include it. Seriously, this is the most broken system I’ve encountered on the ‘net ever; Comcast has just essentially guaranteed that I’d rather pith myself than ever become a customer of theirs.
Having recently finished the fabulous book The Victorian Internet (recommended by Rebecca, who clearly has a handle on what I might like!), I’ve spent a little bit of time obsessed with how amazing the telegraph must have been back in the mid-1800s, and imagining how surreal it must have felt to those who watched it happen. One day, communicating with family across the country might take weeks — and then a year or two later, the same messages might only take minutes to travel back and forth. Before the telegraph, businesses which shipped products and materials internationally might not know whether their shipments made it to their destinations for months; after the telegraph, the same businesses might know within hours of arrival. People had the vision to run telegraph cables along nearly every railroad track in the world, through frozen tundras, and even across seas and oceans, all in the name of making the world a little smaller. I really am in awe.
Of course, this all makes me that much sadder to learn that Friday, Western Union discontinued their telegram service, after 155 years in the telegraph business. (Just to clear up some word confusion: telegraphy is the process of sending messages using Morse code, and early on, the term “telegram” came to refer to the messages themselves.) Western Union was pretty much critical in the development of the telegraph network in the United States; it strung the first transcontinental line in 1861, introduced the first stock ticker in 1866, created elaborate schemes which allowed the secure transfer of money beginning half a decade later, and beginning in 1974, was the first company to send aloft its own batch of communications satellites (the Westar system) to handle its messaging needs. Alas, electronic mail and instant messaging dealt the telegraph system a death blow, making Western Union’s move unsurprising.
It’s been a bit of a busy week; I’m part of the faculty group that’s teaching the second-year medical school hematology course right now, meaning that I’ve been waking up about an hour and a half earlier than normal, teaching for most of the morning, starting all the other work I have to do around noon, and getting home feeling like I’ve been run through the ringer a little bit. That being said, teaching is a lot of fun, and it’s a hell of a reminder of how much I’ve learned since I was in the same class eight years ago back in New York.
Oddly, my respite from the world of medicine this week has been task-guided learning of a new programming language, Java. Towards the end of last week, Matt got the idea of starting up a Jabber server linked to his übersite MetaFilter, and really wanted people to be able to use their MetaFilter usernames and passwords to log into new service. He decided to try out a server that’s coded entirely in Java and has an open, extensible architecture, and asked me what I knew about getting it to talk to his user database. I started looking into the app, and quickly realized that Java is built from the same elements as are most of the other languages I know well, something that went a long way towards putting to rest my fears about delving whole-hog into the guts of the server. A few hours later, I had put together the code that Matt needed, and early this week, I wrote an plug-in from scratch which allows regular users to see a list of all the active users of the server. And while I wrote the first set of tools — the authentication modules — in response to Matt’s need, the goal of getting my feet wet in Java motivated my development of the plug-in as much as did the development of a useful tool for the MetaFilter community. For me, that’s the best way to start to learn a new technology: realize a need, discover that the technology is the best way to fulfill that need, and jump in.
Back in October, I wrote about some Bank of America customer deciding that he would use my Gmail account’s address as the destination for all of his online banking notices, and about how the BoA reps painstakingly claimed to not be able to do anything to deal with the error. The story ended OK, though — I gave them a second chance by calling back a few days later, and ended up getting a competent manager who found the right accountholder and then called him to ask him to correct his error. For two weeks or so, the notices stopped — but then they started right back up again, with the same last four digits of the account number. The realization that the same person put the wrong email address into his BoA account preferences a second time made my brain hurt, so I just put it on the back burner and hoped that it would sort itself out (ha, ha). Alas, they kept coming, so today, I called BoA again.
In contrast to that first phone call back in October, this time the company performed admirably. The first-tier rep understood how annoying this is and got me to his manager quickly (saying that he didn’t have the authority to browse the account database or cold-call customers). The manager spent a few minutes looking up every accountholder with the same first initial and last name as me (which corresponds to the format of the Gmail account), and in about four minutes, she had him. She promised that as soon as we hung up, she’d again contact him, and she’d also leave a detailed note in my account so that if when this happens again, it won’t even take this long to handle.
As frustrating as bad customer service is, good customer service can be even more gratifying.
Jan 17, 2006 | Internet | Television
Lately, RCN has been running commercials in the Brookline market that involve a guy coming on-screen and explaining ways that RCN feels people can get more out of their cable internet connections. The guy runs through the steps needed to complete some task that RCN has determined will make using a broadband connection better; the commercials are pretty hysterical, if only because they’re both totally low-rent and pathetically simple-minded. (And better yet, they’re about 50% louder than the content that precedes and follows them, meaning that the guy is always shouting at you.) You’d at least figure that RCN would use the opportunities to address the threats that today’s internet (and specifically broadband) users face — phishing attacks, viruses, port scanning and security exploitation — but in fact, you’d be wrong. The first commercial we saw involved the guy literally explaining — in as rapid-fire a way as posisble — how to set up Outlook Express for an RCN account; the next one actually walked people through power cycling their cable modems. (Shannon turned to me during the tenth or so time we’d seen the power-cycling commercial and asked, “Do you think RCN is aware that they’re the ones responsible for people having to power cycle their cable modems in the first place?” Alas, no, they’re totally unaware of that fact.)
I’m sure that the idea of RCN using its own television bandwidth in a combined effort to promote its service and educate its users looked great on paper, but on the implementation side, it’s pretty awful.
In an effort to cut down on spam email, a few years ago I put together a clean little framework for a contact form, and put it up in all the relevant places so that people could still send me the occasional note through the various websites that I host. Lately, I’ve been getting a bit of spam submitted through the forms, more annoying than voluminous, and then tonight I learned from Matt Haughey that he’s even seeing a steady stream of spam submitted through the “suggest a post” function of his website PVRblog. It’s amazing to me, only inasmuch as it’s clear that the content spammers are now literally shoving their bits into any and all <textarea>s they can find on the web, much like that dog in heat that won’t stop humping your lamppost.
In a combination of what seems to be a weird quirk and a slew of not-so-bright internet users, MSN’s most recent search engine update has brought a little bit of unanticipated fun to my email inbox.
About two weeks ago, I noticed that I was starting to get quite a few odd emails sent my way via my send-me-an-email webpage. I couldn’t really find a common thread running through the emails; the topics were diverse, the people sending the emails were spread all over the map, and none of it looked very spam-like. (Oddly, I do get the occasional spam manually submitted through that webpage, something that always both confuses and amuses me.) I figured that the page had ended up linked somewhere and that things would die down, but the frequency of the emails just accelerated over the past week. Finally, I modified the script that runs behind that webpage so that it passes along to me the webpage that referred the sender to my contact form, and learned something interesting: all of the senders were coming from an MSN Search result page for the phrase “send mail”. Going to that page, I see that my contact form is the sixth hit, and is the first hit with a title that might imply that it’s a generic email interface. Apparently, users of MSN’s search engine are following those clues, clicking through to my contact form, and sending their emails straight to my inbox. Today alone, I’ve received two resumes, best wishes and prayers on my upcoming exams, and an attempt to submit a late sociology assignment, and the day’s only half-over.
What’s totally baffling to me is why the senders don’t notice that they’re never asked for the recipient of their email, and in the case of that last sender today, how the obvious lack of a facility to upload documents failed to warn him that his “attached” late assignment wasn’t really going to work out so well. I started figuring out how I should modify the page to convey to viewers that it’s only a way to contact me, but then decided that I’m having way too much fun seeing all these emails pop in. We’ll see how long I keep getting misdirected notes, and how long the page stays in that first tier of MSN Search hits.
Congrats to Matt for launching the latest member of the MetaFilter family, MeFi Projects. The main MetaFilter site has a longstanding rule banning members from self-linking (writing posts which link to anything in which they’ve had a hand); the new site is specifically designed to allow those kinds of links, and let members put their projects up on display for everyone else to see. Based on the amazing creativity that’s been displayed by MetaFilter members in the past, I’m interested in seeing what comes of this.
About a month ago, I started getting mail to my Gmail account from Bank of America that contained a bunch of information about bank account deposits, withdrawals, and balances. Trouble is, it isn’t my bank account; all the emails just say something to the effect of “This is an alert for the account with the last four digits XXXX,” and then tell me to log into my online banking account to see details about the alert. The emails come at the tune of one or two a day, and have nothing in them to indicate how I can let Bank of America know that some accountholder put the wrong email address into their preferences.
Tonight, I called BoA’s online banking customer service department and explained the issue to them. The woman put me on hold for a few minutes, and then came back to tell me that there’s nothing they can do about it, and that I should “just ignore the emails.” I was a little incredulous, and asked if they really don’t have a way to search their database by email address, figure out the accountholder, and contact them to let them know their error, and she said that that was all true — the only way they can search their records is by account number. I asked for her supervisor, who came to the phone and repeated their inability to do anything at all. I reiterated that I had the last four digits of the account number, and she said that there was still nothing they could do. She recommended that I just delete the emails, and hope that the owner of the bank account comes to realize his or her error.
Now, being a database programmer, I know that she’s wrong, and that there’s certainly someone within the BoA system who has the ability to search their database by email address. (For example, if an investigator from the Department of Homeland Security called them and told them that they had intercepted a suspicious email, would they really send the DHS rep packing?) What makes me sad is that they’re just plain unwilling to try. When I explained that we have five accounts with BoA, it didn’t make any difference; when I explained that it was hard to justify continuing to use a bank that was so unwilling to try to do the right thing, it made an equal amount of zero difference. So now I’m forced to resort to reporting the emails to Gmail as spam (which they really are, since they’re unsolicited email that I’ve tried to put a stop to by contacting the originator), and writing a letter to the (un-emailable, un-faxable) escalation department at BoA seeing if anyone there realizes the stupidity of this. And when we eventually leave Boston, we’ll see whether BoA retains our business…
On the perfect day for it, Flickr announces photo printing services! This makes me an awesomely happy Flickr user. Right now, the services appears to be limited to people who live in the United States, and allow you to have prints mailed to you or have them printed to any Target store (another hoo-rah from me!). You’ll also have to set your printing preferences before the “Order Prints” button will show up above photos, and everyone’s default is to only allow themselves to print the photos they’ve uploaded unless they specify otherwise. (I’ve set my photos so that anyone in my contact list can print them.)
Thanks, Flickr people!
I’ve been enjoying the occasional posts over at Dreamhost’s “official” weblog, posts that are usually chock full of interesting tidbits that relate to running a mid- to large-sized internet service hosting company. Today’s post comes from Josh Jones (who happens to be Dreamhost’s CEO), and talks about the hoops the company has to jump through in order to be able to request additional internet addresses; the part that’s interesting to me is that the rules which govern the handing out of blocks of IP addresses make it downright necessary for smaller companies to play games so that they don’t get caught without any additional addresses to give their customers. It’s the sort of situation that the next generation of IP addressing (IPv6) was designed to solve, by giving organizations blocks of addresses so big that they’d be able to provide unique ones to over 18 quintillion devices — but most people don’t see IPv6 achieving universal support for the next half-decade or so. So let the addressing games continue!
Sep 21, 2005 | Internet
Damn that Mark Paschal! I’ve been sitting on the fact that TypeKey was about to become an OpenID service ever since I noticed (about a week ago) that my profile page included an openid.server link tag, but I was waiting to mention it until the service started working and went live. Then today, I noticed that Mark went and scooped me, and when I went and tested it out it worked perfectly! (Seems logical that Mark would scoop me, though, seeing as Mark works for the company that created TypeKey, Six Apart…) I’m glad to see more services supporting the OpenID standard; it’s a standard that will work best when services are created that link OpenID identities to layers of information that vouch for a person’s real-world identity, and TypeKey is a good start in that direction.
Remember two weeks ago, when a sales rep of the internet service provider Globat demonstrated his amazing lack of empathy for the people of Plaquemines Parish? Well, here’s an example of the other, shinier side of that coin: in addition to matching their customers’ donations dollar for dollar, Dreamhost gave a year’s free webhosting to all of their customers with billing addresses in the affected areas of the Gulf Coast. That’s very nice to see, and I’m glad to know that for every company like Globat, there exists a Dreamhost.
Does anyone know of any other good ISP-related stories that have come out of Katrina?
A little while ago, during the thick of things in post-Katrina New Orleans, I asked if anyone had found a decent infographic that helped explain both what led to the waterlogged city and how the situation was changing. One of the commenters pointed me in the direction of the New York Times interactive feature (really, a full-fledged Flash application), and I’ve been following it ever since. The people at the Times have kept the app updated nearly daily, and have added feature after explanatory feature; it’s a great resource for synthesizing all the information about levees, pumps, canals, neighborhoods, and everything else.
An honorable mention also goes to CNN’s offerring, which I first saw this morning. In particular, the CNN app has maps with overlaid information about estimated water depth by date ranges, showing where the water was its deepest, and how engineers have progressed in pumping out areas of the city.
Sep 13, 2005 | Government | Internet
How funny — it looks like the folks who run FEMA’s internet services don’t have an email server designated for the organization (see for yourself here), meaning that any and all email sent to an @fema.gov address is bouncing back as destination unknown. Seeing as a bunch of the email addresses on FEMA’s contact page live at fema.gov, it’s not only embarrassing, it’s another small measure of how the organization doesn’t quite seem to know what it’s doing.
(For those of you who aren’t such internet geeks, the best brick-and-mortar analogy for this is that it’s as if FEMA doesn’t have a mailbox or mailroom — right now, from the internet, there’s no way to get email to the organization at all. And for those of you who are big internet geeks, you probably know that the relevant RFC says that if there’s no MX record for a domain name, mail transport agents should fallback to using an A record — but the machine that lives at the A record address for fema.gov doesn’t have an SMTP server running, so the fallback is also falling flat on its face.)
In the past, I’ve been a reasonably strong defender of Paypal, a company that a not-insignificant number of people hate (with the fury of a thousand suns) for having what they claim are capricious policies and an impenetrable bureaucracy. (Most recently, I participated in a thread on MetaTalk, the discussion board for MetaFilter, defending Paypal’s general policies and behavior.) I have to say, though, that the experience that the folks over at Something Awful have had with Paypal over the past 24 hours has completely swung me to the other side of the fence. (Unfortunately, the main Something Awful servers are located in New Orleans, and thus are out of commission; the story has unfolded on the temporary server, and you can read the posts as information trickled in.)
As I understand it, the story is this: Rich Kyanka, the guy who runs Something Awful, set up a donation fund via Paypal to collect money for the Red Cross hurricane relief efforts. In under seven hours, he had collected over $3,000 an hour — nearly $20,000 total — and was nearly speechless in his admiration for the members of the site that had given so selflessly. Soon thereafter, though, Paypal shut down the account, claiming that they had received “more than one report of suspicious behavior” from his “buyers.” He was shunted into an automated dispute resolution process that demanded he provide some sort of “proof of delivery” for all the donation transactions; hilariously, Paypal’s web app won’t let a recipient of money proceed with the dispute resolution until he or she chooses one of the people who reported suspicious behavior from a pull-down and then upload tracking information, but the app didn’t list a single person as having made a complaint, so Rich wasn’t even able to proceed with the resolution request. (And the whole time, the $20K was sitting in Paypal’s accounts, not available either to Rich, the Red Cross, or the original donors.)
Rich had a hard time getting an actual human on the phone, and when he did, the woman wasn’t able to explain anything about why he had actually been shut down. (Looking over Paypal’s Acceptable Use Policy, neither can I.) She told him he’d have to send a fax to Paypal with all sorts of personal info (driver’s license, bank statement, credit card statement); after doing some sort of review of that information, they still refused to release his account. It wasn’t for many more hours that he finally received information from Paypal explaining that the only resolution they would agree to was a refund of all the donor’s money to each individual person. Stunning — Paypal’s seemingly-random jackassery means that $20K of money that could and should be going to the relief effort is now being returned.
Yep, I’m at the point where I can admit that perhaps Paypal does suck.

Does anyone know whether Amazon has waived the normal 2.9%-plus-$0.30 fee that they assess on donations made to the American Red Cross through the Amazon Honor System? According to their charities page (and an old c|net article), the company explicitly waived the fees for 9/11 donations, but there’s not a word on the Amazon website about whether that’s still true.
For the past few days, I agreed with the general sentiment on the web that Amazon’s lack of any prominent mention of ways to contribute was odd (especially given its quick and overwhelming response to the tsunami earlier this year, converting their entire homepage into a plea for donations). This just extends that baffled sentiment a little bit more for me — if they are waiving the fees, why don’t they make that clear? And if they’re not waiving the fees, why wouldn’t they?
I’d love it if someone knew the answer to this; until then, though, I’d recommend either donating to the Red Cross directly (though their website has been absolutely swamped, and is at times totally inaccessible) or to the Red Cross via Yahoo (who has pledged to pass 100% of donations through to the Red Cross).
Congrats go out to Maggie for Mighty Goods (her kickass shopping weblog) showing up as a nominee in BusinessWeek’s Best of the Web survey. (It’s in the Shopping category under @ Play.) It’s up against a few sites that aren’t so shabby in their own rights, but since I’m a bit partial to the world of weblogs, I gave Maggie my nod. Go do your part!
Aug 31, 2005 | Internet
Fascinating: Plaquemines Parish, a small parish in deep southern Louisiana, hosts their government website using Globat, and it appears that all the people interested in checking in on the parish and its residents have put the website over its daily bandwidth allotment. (Here’s a screenshot of what the home page looks like right now, and here’s a Google cache of the page before it hit its bandwidth limit.) I figured that I’d do my good deed for the day and call the hosting company to see if they’d be willing to suspend the bandwidth limits for the time being, so I called the only number I could find on their website, (877) 2-GLOBAT. I got a sales guy who said the exact following: “If a customer goes over their bandwidth, we shut ‘em down, no matter who they are.” I asked whether he’d either put me in touch with someone in the corporate structure who’d be willing to consider helping the parish out — after all, the people in the parish whose job it is to deal with this might be otherwise indisposed (and probably without phone service!), and he said no. He was uninterested in giving me his name, and abruptly ended the conversation.
I guess it’s rare that I’m this stunned at the total lack of empathy some people can have.
Update: whether it was this post, Sara’s webhostingtalk.com post, or just plain second thoughts, the Plaquemines Parish website is back up.
Warning: this might be one of my geekiest entries in a while. If you don’t care one whit about such things as internet protocols and development bugs, you’ll either want to ignore it, or read it and mock me.
After realizing that the two torrents I posted over the past 24 hours didn’t work at all, I started digging into the BitTorrent tracker I use (BlogTorrent) to see what the problem could be. After a lot of excavation, it turns out that BlogTorrent (and Broadcast Machine, its more mature cousin) is a little deaf to one of its configuration parameters, a parameter that’s likely to be less-often used, equally likely to be safely ignored in a bunch of circumstances, but is nonetheless both important and mandatory on network setups like mine. I posted a bug on the Sourceforce page for the tracker, so we’ll see what happens.
All this being said, I have to admit that I didn’t find it very easy to debug the entire BitTorrent conversation, a fact that made it much harder to find the problem and work out where it was located. BitTorrent itself uses a dead simple protocol, but I’m underwhelmed by the information about peers, seeding, and the like that’s available from BlogTorrent and the standard BitTorrent clients. I had to do a lot of webserver logwatching and launching of netstat dumps to figure out what was broken; I’d love to find a tracker which provides enough data so that I don’t need to repeat the performance.

This weekend, my brother passed on a link that’s kept me entertained ever since. Where the Hell is Matt? is the site of Matt Harding, a self-described “28-year-old itinerant deadbeat from Connecticut” who’s traveling the world and posting fantastic missives along the way. On top of this, though, Matt has taken up videotaping himself dancing at all of his destinations, and the clip montage he’s posted is pretty much the best thing I’ve seen on the web in a while. (My favorite is his clip from the Impenetrable Forest in Uganda — it’s both creative and funny.) The whole package is oddly life-reaffirming — a guy who quit his job to wander the Earth and dance! — and easily has made its way into my daily-read list.
(I’ve put up a torrent for the large QuickTime version of the clip montage, so feel free to treat Matt’s bandwidth gently and get the movie from the torrent instead. I asked Matt for permission, though, so if he’s not OK with it the torrent might disappear.)
Interesting — it looks like a few inquisitive folks have figured out a way to get onto Google’s soon-to-be-announced talk service using any ol’ Jabber instant messaging client. I’ve been hanging out online for a little bit now using Adium (others are doing just fine using iChat and Trillian), and shockingly, it’s just like instant messaging! This isn’t entirely fair, though, since Google is also developing a dedicated client that’s rumored to place audio and video chat on par with text instant messaging; it’ll be interesting to see what they use for the audio and video components.
(Note that if you follow the instructions and hop onto Google’s IM servers, you might find that your connection occasionally dies; I’m assuming that they’re readying the service for tomorrow’s rumored release. Just so you know!)
Aug 14, 2005 | Internet
Over in the little kingdom of Wikipedia, a war is brewing that’s just pissing me off. There’s a specific user who seems to have an enormous, overarching hatred of Ajax (the web development technology encompassing asynchronous JavaScript, the Document Object Model, and DHTML), and in the furtherance of his hatred, appears to be absolutely hellbent on pissing all over everything related to it on Wikipedia. (He even chose his name to be a pun on the name of a well-known user who is proficient in Ajax technologies.) The user has been involved in huge revert wars on the Ajax article itself, and recently has also started monomaniacally adding a critical section to the page of Jesse James Garrett (the author of the article coining the Ajax name). Whenever anyone challenges his edits, the user throws a tantrum, makes wild accusations, and reverts the page to the last version he had defaced. (For example, when I edited his section to remove a falsely-attributed quote, remove a bit of bile, and delete a pointedly biased link to the defacer’s own website, he just called my edits “vandalism” and reverted them.) As of today, he’s managed to get an administrator to lock both pages from further edits, freezing them in a state that includes his vomitus.
To me, this highlights my biggest frustration with Wikipedia — that in an effort to allow communal access and editing of the encyclopedia, it makes the entire product susceptible to childish wailing and harrassment, and only pages that become high-profile develop enough community defense and generate enough community discussion to keep the miscreants at bay. When the pages aren’t high enough profile, such as the the case with the pages on Ajax and Jesse James Garrett, users with grudges might be able to pull the wool over the eyes of a gullible administrator and get him or her to intervene, lock the pages, and prevent anyone else from having an opinion. It’s all just screwed up beyond belief.
What can you do? I’m not all that sure. For now, you can go over to the relevant pages — the discussion page on the Jesse James Garrett article, the discussion page on the Ajax article, and the talk page for the admin user who locked the pages — and engage in reasoned discourse on why this whole mess is stupid. Perhaps logic and discussion might help (although I doubt it, since I’ve been trying for a week or two without much success). If that doesn’t work, perhaps others can try to bring this in front of the arbitration committee over at Wikipedia, since I’m rapidly losing both the energy and the interest in saving Wikipedia from itself. Maybe someone else has a better answer, though; I certainly don’t.
Update: a nice user dropped me an email that comments were totally broken; it’s fixed now.

This weekend, I finally got around to helping my brother get some files off of an old Powerbook Duo 230 that he’s been keeping in storage; I was pleasantly surprised that I was even able to get the laptop onto the internet. I’ve put a few photos up on Flickr, just for kicks.
Jun 20, 2005 | Internet
Reason number 4,352,877 that you should run as far away from America Online as you can: AOL is now refusing to accept any email that contains a link to MetaFilter, saying that MetaFilter “is generating substantial complaints from AOL members”.
What jackholes.
Jun 14, 2005 | Internet
Because the NBA has not a single link to the audio stream for tonight’s NBA Finals game 3 on their home page, here’s the link to the RealAudio stream of the San Antonio radio coverage. You probably have to be an NBA Insider member to listen to that; the most galling thing is that I am a member, but in order for me to be able to use the service for which I’ve paid, the NBA made me dig around in my Real Player history in order to find a working link. (I’m on call tonight, and don’t have easy access to a TV; the radio coverage is all I have!)
I hate hate hate websites that are designed for advertisers and marketing tie-in partners rather than for users. And that goes doubly so for websites that take users’ money and don’t put the services that those users pay for right up front.
Update: the links appeared on NBA.com at 9:00 PM on the nose. So despite the fact that the NBA forces local affiliate radio stations to stop streaming pregame coverage 30 minutes before the game starts, the NBA doesn’t provide coverage to its paid customers until the exact moment of gametime. Total morons, they are.

To be filed in the bin of continuing abuses of the net by companies that should know better: today, I got an email from the domain registrar Dotster (who I have patiently asked about a dozen times to stop sending me their ads) claiming that now’s the perfect time to register my .DE domain name for use with my Delaware business. What’s the problem with this? The .DE domain is the national top-level domain for Germany! To me, it seems a bit, you know, presumptuous to advertise another nation’s top-level domain as perfect for registrants in a measly U.S. state. (And according to the official German registrar, it’s also a mandatory condition of .DE domain registration that the administrative contact maintain a German postal address that can receive any and all legal and court documents that might be filed against the owner of the domain; I wonder how Dotster is dealing with this little stipulation.)
The city of Wilmington, Delaware has already started squatting in the domain space, but using a domain name that I’m certain causes them more trouble than it’s worth (“no, no, no, that’s the word ‘wilmington’, then a dot, then the letters D-O-T, then another dot, and then the letters D-E!”). With the jackassery of Dotster, though, I’m sure that’ll change.
May 3, 2005 | Internet
(From the very beginning, I’ll acknowledge that this is one of my geekier posts.) At the very top of the list of coolest ‘net-related things I’ve seen this month is the EarthLink R&D project offering a full-fledged IPv6-supported network to anyone who wants to play in their sandbox. The fact that an EarthLink lab has worked on this, and released this, makes me happy that there are still people using easily-accessible tools to push at the edges of the internet.
For those who are technically-inclined, you probably already know what this means; for those who aren’t, let me offer a short explanation. Right now, every computer that can be accessed on the public internet has a unique address, and there are around 4.3 billion “available” addresses. The reason for the quotation marks, though, is that this is a theoretical maximum, and the reality is that about half of these addresses aren’t available for use, which means that there’s an ever-present worry that we will run out of addresses to use on the internet. One solution to this problem is a new method of addressing internet-enabled devices, a method called IPv6, and with it comes the ability to support 340 undecillion addresses (or 3.4 x 1038 addresses, or 340 billion billion billion billion, addresses — which is enough for 670 quadrillion addresses per cubic millimeter of the Earth’s surface). Since we have somewhere around a decade before the need to move to IPv6 becomes urgent, though, it’s not yet in widespread use on the internet.
What EarthLink’s R&D project allows you to do today is buy a Linksys wireless router, download a custom firmware for the router, sign up for an account, and set up your own IPv6 network lickety-split. And the cool thing is that the wireless router will continue to protect the network from access from the outside on the old-style network (the one addressed using the old scheme), but will let you configure full access via the new addressing scheme — which means that you can set up public servers! That’s just cool.
I don’t have a router on which to play with this quite yet, so I’ll be interested to hear other peoples’ experiences. Perhaps in the next week or two, I’ll justify playing a bit myself as well…
How cool — Brookline looks like it’s going to go wireless! Of course, there aren’t any guarantees that the plan will succeed; attempts by other cities to provide universal wireless access have met with intense objection from the telecommunications providers that would actually have to start competing for business, providers that carry a lot of weight in the various state legislatures. (For a hilarious look at the view telecoms take of cities moving to provide WiFi access, read this account of Verizon’s CEO losing his mind during a conference call when he was asked about San Francisco’s plans to blanket the city with wireless.)
Nonetheless, it looks like there are a few factors that might make Brookline’s attempt more likely to take root. First, it seems that Brookline is looking to deploy wireless as much for city use as for public use; reading the Wireless Committee minutes and looking at the various presentations the committe has requested makes it clear that the police and fire departments, the parking enforcement department, and the various divisions of Public Works all are looking to invest heavily in using wireless communication. (And for those of you who’ve spent any time in Brookline, you know that the most important — and lucrative — one of those groups is the parking enforcement one, which very well might be able to pay for the wireless infrastructure itself!) It’s unclear whether the telecoms would have enough juice to fight a battle against such a strong interest.
Second, in my time here in Brookline, I’ve gotten the impression that the town has an incredibly strong ethic that resists bending to corporate interests. When I had an ongoing problem with my cable service, a Brookline ombudsman was able to put me in touch with a senior corporate representative of our cable company pretty much instantly, and shared with me the fairly restrictive contract that Brookline signed with the company detailing expectations of service and responsiveness. It’s vigilance like this — possible because of the small size of Brookline — that’ll probably work against any efforts by the telcos to oppose wireless plans here.
Only time will tell, but it’s neat to think that Brookline’s going to go forward with this!
Hey, cool — the rumors were true, Yahoo has acquired Flickr. That’s awesome; it’s a fabulous web application, constructed by people who clearly get the web and have the programming skills to build an extremely usable interface, so it’ll be exciting to see how Yahoo integrates Flickr into its offerings. It’s nice to see that it will remain separate from Yahoo’s own photo service for the time being, since what makes Flickr so unique is that it’s not a generic store-and-print-your-photos service, but rather seems to be centered on using images to create communities and interconnections. It’s also nice to see that Yahoo will be throwing its resources at expanding capacity and lowering costs, which is always a bonus.
Congrats to Stewart, Caterina, and all the other people at Flickr!
Whoa — Google Maps. When did this appear? (Oh, it looks like it’s new as of today!) The implementation looks awesome (as you’d expect), right down to the three-dimensional shadow beneath the locators. I’ll definitely have to play with this a bit more later today! (Update: Rafe says everything I’ve thought of so far, and then some, so all I’ll add is that I’m equally impressed.)
So, I’m at the point where I want to take Firefox and shove it straight into my Powerbook’s trashcan. It’s become an unpredictably unreliable application, and it’s not clear to me that there’s anything I can do about it except trawl Bugzilla, add my experiences where possible, and hope and pray that sometime it’ll all get fixed. Some of my current frustrations:
Occasionally, issuing any keyboard-based shortcut command (e.g., CMD-T to open a new tab, or CMD-W to close a tab) issues that command twice. And while this is merely annoying at times, it’s downright infuriating at others — like when I intend to close the currently-open tab, but Firefox instead closes it and the one beside it containing something on which I’m actively working, completely losing whatever it was I was doing. (Oddly, when Firefox finds itself in this state, certain other keyboard shortcuts stop working entirely, like CMD-Q to quit.) There’s an entry on Bugzilla for this, but it’s still listed as an unconfirmed bug. That entry also links the behavior to the use of Java, which I’m not sure is the only cause, since there are times that I’ve seen the behavior when there isn’t anything Java-related open in any tab or window.
At other times, Firefox stops allowing me to enter any text whatsoever into any text box, including the address bar, the search box, or any text input field on a web page in a window. (There are times when I have multiple Firefox windows open, and interestingly, when the bug happens, it only happens in one of the windows.) About 75% of the time, I can “fix” things by switching to another app and then back to Firefox; the other 25% of the time, there’s nothing I can do but close the affected Firefox window entirely, losing all the tabs that are open in that window, including any work I might be doing in those tabs. (There’s a Bugzilla entry on this one, as well.)
Then, there are certain bits of Flash content that will bring Mac Firefox to its knees, and (in a common theme) force me to force-quit the browser and lose all of my work. As far as I can tell, there are a bunch of open Bugzilla entries for this (172175, 233702, 244987, and 106397 are the ones I found in my not-so-quick survey), all of which have in common the fact that if you can see the Flash object that’s causing the problem, holding down the mouse button lets it continue to run, but doesn’t let you salvage your browser or your work.
And lastly, there’s the occasional thing that, while still a bug, has less to do with reliability and more to do with good ol’ missing, broken, or just plain odd functionality. My best example of this is that on the Mac version of Firefox, you cannot open a new window — or do any menu-based tasks — when the only window open is the either the Download Manager or the Preferences window. The interesting thing to note about this is that, in its most basic causal form, the original bug was filed on December 9th, 1999, and around 50 other bug reports have been marked as duplicates of this bug, meaning that people have run into it over and over again without the error being fixed. (And that doesn’t count the five or six currently open bugs that look like they’re headed to being classified as duplicates, nor does it count the bugs that were classified as duplicates of other bugs which were then classified as duplicates of this one. Holy recursion!)
So, lately I’ve found myself having both Safari and Firefox open, and using Safari whenever I need to do any real work. That’s sad; I like having the same browser on my Macs and PCs, and I like the openness of Firefox, but I don’t like the number of times I’ve lost important sites or work to its bugginess.
Interesting — while updating a setting on one of Shannon’s domains today, we noticed that Dotster added the .info version of the domain to her account for free last week, without asking or notifying her in any way (other than it just showing up in her account list). Shannon and I both got a number of notices from Dotster over the past few months that they were giving away 25 free .info domains to all of their customers, and we ignored the notices. The logical conclusion from this is that we just weren’t interested, right?
If my assumption is correct that she’s not the only one for whom they did this, then that begs the question: isn’t this a profound waste of domain names, and particularly, of domain names that were likely not registered by the owners of their .com correlaries as conscious decisions?
In news both interesting and frightening, the domain name for Panix, the oldest commercial internet service provider in New York, was hijacked out from under them on Friday night. Both the notice about the hijacking and various progress reports about how it’s been handled by the involved companies have been posted on Panix’s temporary home on the net and over at the North American Network Operators Group (NANOG) mailing list (search for “panix.com” and you’ll find the posts), but the short version is that the registrars have handled it horribly, leaving Panix without use of its primary domain name for going on 48 hours now. And what people need to remember is that, during the time Panix hasn’t been in control of the domain, whoever was responsible for the hijacking can easily have had computers running which have been able to capture every single username, password, piece of email, file, and whatever else clients have sent to what they thought were valid panix.com machines. Pretty frightening.
The thing that’s most surprising to me is that this hasn’t gotten a whole hell of a lot in the way of press; as of right now, searching Google News for “panix” brings up only three relevant news articles. Honestly, this seems to me to be the perfect example of how the internet has expanded faster than the ability of the relevant organizations to protect the immense time, energy, and money people invest in it, but the story’s not getting much coverage right now. I imagine that if microsoft.com were the domain hijacked, we’d be hearing more about it, but it’s not like Panix is a small fish, it’s just not a blue whale — and that’s enough to shove the story off the radar over a holiday weekend. Alas.
There’s a concerning thread over at WebHosting Talk about a user being charged ten bucks by GoDaddy for ostensibly having incorrect contact information in his domain name registration information, despite the user’s claims that all the information was correct. Someone from GoDaddy actually posted details, as well as information about the policy regarding the charges (that they only charge if incorrect information is actually found); nobody has been able to find the actual user agreement that states this, though, and the original user continues to insist that his information was correct and that GoDaddy has begun ignoring any of his attempts to contact them in an official way.
Given that there’s a new policy coming into effect tomorrow that makes it a lot easier to lose your domain names (via domain transfer requests by nefarious others) if your contact information isn’t perfectly correct, now might be a good time to hop onto your registrars’ websites and verify that everything is as it should be. Most registrars will also allow you to “lock” your registrations so that domain transfers cannot take place without you manually going to their site and reversing the lock — GoDaddy allows this, as does Register.com and even the hoary Network Solutions. When this lock is in place, no transfer request can go through at all (in theory), protecting you from illegitimate transfer requests even when you’re away from your email for more than five days.
I’m with the other Jason in saying that the new policy is supremely idiotic, if only for the incredibly short notification period that is destined to lead to some pretty major domain name losses over the coming months. (After all, it’s reasonably hard to guarantee that you see and trust every single email that’s sent to the address in your registration records, given that this email address sits out there in public and manages to attract metric tons of spam, viruses, and phishing attempts!) And in reading the actual text of the policy, it seems that there’s a window created for registrars who want to side with consumers rather than ICANN and refuse to automatically grant transfers after five days — but that’s my non-legal read of it, which I’m not so sure I’d trust. Nonetheless, it’ll be interesting to see if any registrars become consumer-friendly in this regard.
(If you’re interested, links to the actual ICANN policy, with quotes of the relevant sections, are available in the extended version of this post.)

{kind=link}
{kind=link}